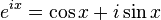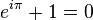重绘的问题长久以来都是图形渲染的性能瓶颈,围绕这一话题的优化也层出不穷:在移动端,有我们熟悉的Tile Based Rendering架构[8];在渲染管线的进化历程中,也先后有人提出了Z-Prepass,Deferred Rendering,Tile Based Rendering以及Clustered Rendering,这些不同的渲染管线框架,实际上都是为了解决同一个问题:当光源超过一定数量、材质的复杂度提升后,如何尽量避免Shader中大量的渲染逻辑分支,以及减少无用的重绘。有关这个话题,可以读一读我的这篇文章[9]。
通常来说,延迟渲染管线都需要一组称之为G-Buffer的Render Target,这些贴图内存储了一切光照计算需要的材质信息。当今的3A游戏中,材质种类往往复杂多变,需要存储的G-Buffer信息也在逐年增加,以2009年的游戏《Kill Zone 2》为例,整个G-Buffer布局如下:
void Start () {
colorID = Shader.PropertyToID("_Color");
prop = new MaterialPropertyBlock();
var obj = Resources.Load("Perfabs/Sphere") as GameObject;
listObj = new GameObject[objCount];
listProp = new GameObject[objCount];
for (int i = 0; i < objCount; ++i)
{
int x = Random.Range(-6,-2);
int y = Random.Range(-4, 4);
int z = Random.Range(-4, 4);
GameObject o = Instantiate(obj);
o.name = i.ToString();
o.transform.localPosition = new Vector3(x,y,z);
listObj[i] = o;
}
for (int i = 0; i < objCount; ++i)
{
int x = Random.Range(2, 6);
int y = Random.Range(-4, 4);
int z = Random.Range(-4, 4);
GameObject o = Instantiate(obj);
o.name = (objCount + i).ToString();
o.transform.localPosition = new Vector3(x, y, z);
listProp[i] = o;
}
}
然后我们在Update函数中响应我们的操作,这里我使用按键上下健位来操作。
void Update () {
if (Input.GetKeyDown(KeyCode.DownArrow))
{
Stopwatch sw = new Stopwatch();
sw.Start();
for (int i = 0; i < objCount; ++i)
{
float r = Random.Range(0, 1f);
float g = Random.Range(0, 1f);
float b = Random.Range(0, 1f);
listObj[i].GetComponent<Renderer>().material.SetColor("_Color", new Color(r, g, b, 1));
}
sw.Stop();
UnityEngine.Debug.Log(string.Format("material total: {0:F4} ms", (float)sw.ElapsedTicks *1000 / Stopwatch.Frequency));
}
if (Input.GetKeyDown(KeyCode.UpArrow))
{
Stopwatch sw = new Stopwatch();
sw.Start();
for (int i = 0; i < objCount; ++i)
{
float r = Random.Range(0, 1f);
float g = Random.Range(0, 1f);
float b = Random.Range(0, 1f);
listProp[i].GetComponent<Renderer>().GetPropertyBlock(prop);
prop.SetColor(colorID, new Color(r, g, b, 1));
listProp[i].GetComponent<Renderer>().SetPropertyBlock(prop);
}
sw.Stop();
UnityEngine.Debug.Log(string.Format("MaterialPropertyBlock total: {0:F4} ms", (float)sw.ElapsedTicks * 1000 / Stopwatch.Frequency));
}
}